机器之心编译参与:路雪、一鸣
近日,南大周志华等人首次提出使用深度森林方法解决多标签学习任务。该方法在 9 个基准数据集、6 个多标签度量指标上实现了最优性能。
在多标签学习中,每个实例都有多个标签,多标签学习的关键任务就是利用标签关联(label correlation)构建模型。深度神经网络方法通常将特征和标签信息共同嵌入到潜在空间,以充分利用标签关联。但是,这些方法的成功高度依赖对模型深度的精确选择。
深度森林是近期基于树模型集成的深度学习框架,该方法不依赖反向传播。最近,来自南京大学周志华团队的研究者发布了一篇论文,他们认为深度森林的优势非常适合解决多标签问题,并设计了多标签深度森林方法(Multi-Label Deep Forest,MLDF)。
MLDF 使用了两种机制:度量感知特征重用(measure-aware feature reuse)和度量感知层增长(measure-aware layer growth)。度量感知特征重用机制根据置信度重用前一层中的优秀表征,度量感知层增长机制确保 MLDF 根据性能度量指标逐渐增加模型复杂度。
MLDF 可以同时处理两个难题:限制模型复杂度从而缓解过拟合问题;根据用户需求优化性能度量指标,因为多标签评估存在多个不同的度量指标。实验证明,该方法不仅在多个基准数据集、六个性能度量指标上击败了其他对比方法,还具备多标签学习中的标签关联发现和其他属性。
多标签学习该怎么解
在多标签学习中,每个示例同时与多个标签相关联,沐鸣帐号注册多标签学习的任务即为新实例预测关联标签集。多标签学习任务在现实世界中比比皆是,因此该研究领域也吸引了越来越多的注意力。
二元关联(Binary Relevance)方法将多标签学习问题转换为每个标签的独立二分类问题,这一直接方法在实践中广为应用。尽管它充分利用传统高性能单标签分类器,但是当标签空间很大时,该方法会带来极大的计算成本。
此外,此类方法忽视了一点:一个标签的信息可能有助于学习其他相关标签。这限制了模型的预测性能。因此,越来越多旨在探索和利用标签关联的多标签学习方法应运而生。
与传统的多标签方法不同,深度神经网络模型通常试图学习新的特征空间,并在其上部署一个多标签分类器。但是,深度神经网络通常需要巨量训练数据,因而不适合小规模数据集的情况。
周志华教授和冯霁博士意识到,深度学习的本质在于逐层处理、模型内特征变换和足够的模型复杂度,进而提出了深度森林。深度森林是基于决策树构建的深度集成模型,其训练过程不使用反向传播。集成了级联结构的深度森林能够做到类似于深度神经模型的表征学习,而深度森林的训练过程要简单得多,因为它具备较少的超参数。尽管深度森林在传统分类任务中很有用,但此前研究人员并未注意到将其应用于多标签学习的潜力。
用深度森林,解决多标签学习任务
深度森林的成功主要依赖于以集成方式进行逐层特征变换,而多标签学习的重点就是利用标签关联。受此启发,周志华团队提出了 MLDF 方法。简单来说,MLDF 方法使用不同的多标签树方法作为深度森林的构造块,通过逐层表征学习利用标签关联。
由于多标签学习的评估过程要比传统分类任务更加复杂,因此研究人员提出了大量性能度量指标 [Schapire and Singer, 2000]。研究人员还注意到,不同用户的需求不同,算法在不同度量指标上的性能往往不同 [Wu and Zhou, 2017]。
为了实现特定度量指标上的更好性能,周志华团队提出了两种机制:度量感知特征重用和度量感知层增长。前者受到置信度筛选(confidence screening)[Pang et al., 2018] 的启发,重新利用前一层中的优秀表征。后者则根据不同的性能度量指标控制模型复杂度。
这篇论文的主要贡献包括:
首次提出将深度森林应用于多标签学习任务;
实验证明,MLDF 方法在 9 个基准数据集、6 个多标签度量指标上实现了最优性能。
多标签深度森林(MLDF)
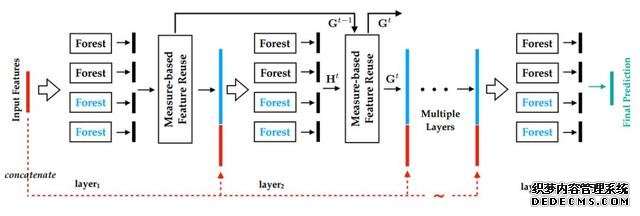
下图 1 展示了 MLDF 的框架。MLDF 的每一层集成了不同的多标签森林(上方的黑色森林和下方的蓝色森林)。
9大数据集6大度量指标完胜,周志华等提出深度森林处理多标签学习
图 1:MLDF 框架图示。每一层集成了两种不同的森林(上方的黑色森林和下方的蓝色森林)。
从 layer_t 中,我们可以得到表征 H^t。度量感知特征重用机制将接收表征 H^t,并在不同指标性能的指引下,重新利用 layer_t−1 学得的表征 G^t−1 来更新表征 H_t。然后,将新的表征 G^t(蓝色)和原始输入特征(红色)级联在一起,输入到下一层。
在 MLDF 中,每一层都是森林的集成。为了提升该集成的性能,研究者考虑了不同的树增长方法,以鼓励多样性,这对集成方法的成功至关重要。
MLDF 用 RF-PCT [Kocev et al., 2013] 作为森林模块,并对森林应用两种不同的树节点生成方法:一种方法是 RF-PCT,它考虑每个特征的所有可能分割点;另一种方法是 ERF-PCT,它随机考虑一个分割点。当然,其他多标签树方法也可以嵌入每个层中,如 RFML-C4.5。
度量感知特征重用
PCT 的分割标准不与性能度量指标直接相关,当指标不同时,每一层生成的表征 H^t 是相同的。因此,研究者提出了度量感知特征重用机制,在不同度量指标的指引下改进表征。
度量感知特征重用的关键想法是:如果当前层的置信度低于训练中设定的阈值,则在当前层上部分地重用前一层中的优秀表征,从而提升度量指标性能。
算法 1 总结了度量感知特征重用的过程。由于基于标签的指标和基于实例的指标存在很大的差异,我们需要分别进行处理。具体来说,基于标签的指标在 H^t 的每一列上计算置信度,基于实例的指标基于每一行计算置信度。计算完成后,当置信度 α^t 低于阈值,则固定前一层的表征 G^t−1,并利用它更新 G^t。
9大数据集6大度量指标完胜,周志华等提出深度森林处理多标签学习
度量感知层增长
尽管度量感知特征重用能够在不同度量指标的指引下高效改进表征,但该机制无法影响层增长,不能降低训练过程中出现过拟合的风险。为了减少过拟合、控制模型复杂度,研究者提出了度量感知层增长机制。
MLDF 是逐层构建的。算法 3 总结了 MLDF 训练过程中度量感知层增长的步骤:
9大数据集6大度量指标完胜,周志华等提出深度森林处理多标签学习
实验
研究者在不同的多标签分类基准数据集上测试了 MLDF 的性能。其目标是验证 MLDF 方法可在不同度量指标上实现最优性能,前述两种度量感知机制是必需的。此外,研究者通过不同角度的详细实验证明了 MLDF 的优点。
研究者选择了 9 个来自不同应用领域、具备不同规模的多标签分类基准数据集。下表展示了这些数据集的基本信息:
9大数据集6大度量指标完胜,周志华等提出深度森林处理多标签学习
表 3:数据集描述:领域(Domain)、样本数(m)、特征数(d)和标签数(l)。
在这 9 个基准数据集上,MLDF 在所有评估度量指标上均取得优秀的结果:98.46% 的情况下性能位列第一,1.54% 的情况下位列第二。根据 6 个度量指标的对比结果,MLDF 夺得第一的比例分别是 100.00%、96.29%、96.29%、100.00%、98.15%、100.00%。总之,MLDF 在大量基准数据集、多个评估指标上取得了最优性能,超过其他公认方法,这验证了 MLDF 方法的有效性。
9大数据集6大度量指标完胜,周志华等提出深度森林处理多标签学习
9大数据集6大度量指标完胜,周志华等提出深度森林处理多标签学习
表 4:每个方法在 9 个数据集上的预测性能(均值 ± 标准差)。•(◦) 表示 MLDF 明显优于(逊于)其他对比方法,沐鸣注册评估标准是成对 t 检验,显著性水平为 95%。↓ (↑) 表示值越小(大),性能越好。